publications
My Google Scholar Page is https://scholar.google.com/citations?user=uH9aTe4AAAAJ
2026
-
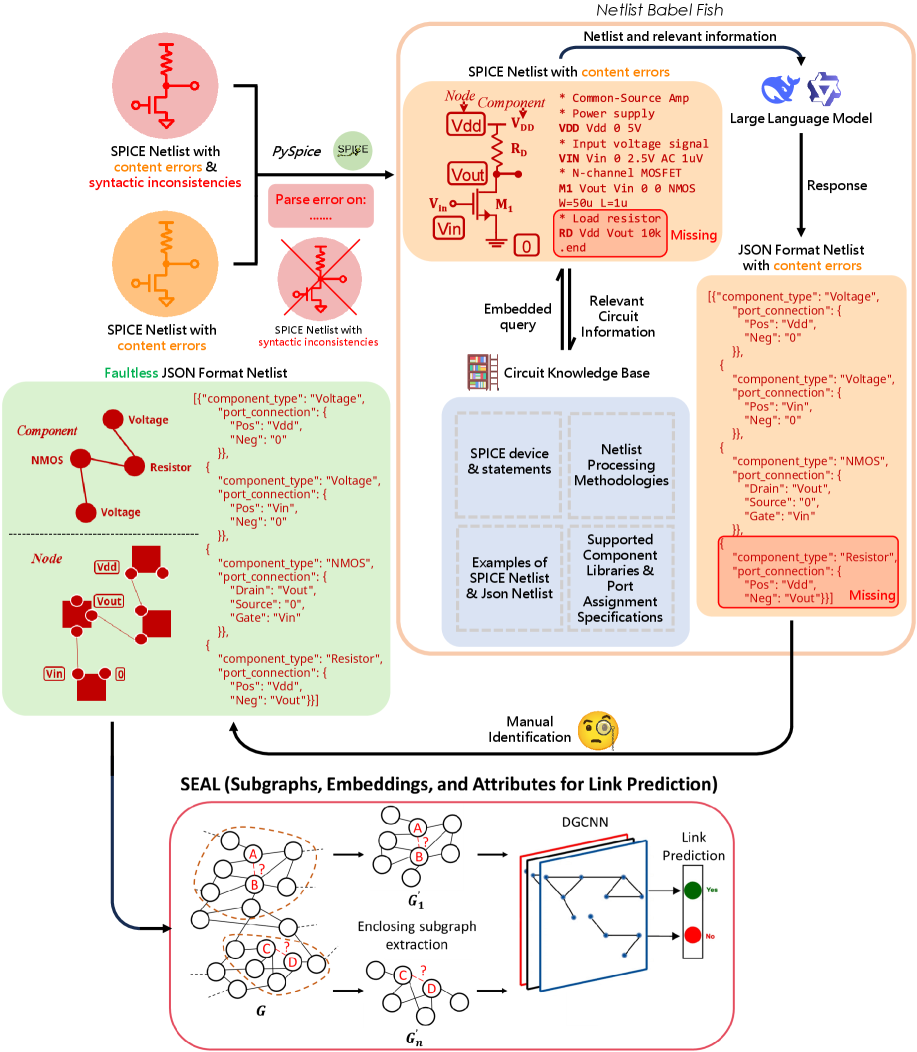 Graph Neural Networks Based Analog Circuit Link PredictionGuanyuan Pan, Tiansheng Zhou, Jianxiang Zhao, and 6 more authorsEngineering Applications of Artificial Intelligence, 2026
Graph Neural Networks Based Analog Circuit Link PredictionGuanyuan Pan, Tiansheng Zhou, Jianxiang Zhao, and 6 more authorsEngineering Applications of Artificial Intelligence, 2026Circuit link prediction, which identifies missing component connections from incomplete netlists, is crucial in analog circuit design automation. However, existing methods face three main challenges: (1) Insufficient use of topological patterns in circuit graphs reduces prediction accuracy; (2) Data scarcity due to the complexity of annotations hinders model generalization; (3) Limited adaptability to various netlist formats restricts model flexibility. We propose Graph Neural Networks Based Analog Circuit Link Prediction (GNN-ACLP), a graph neural networks (GNNs) based method featuring three innovations to tackle these challenges. First, we introduce the SEAL (learning from Subgraphs, Embeddings, and Attributes for Link prediction) framework and achieve port-level accuracy in circuit link prediction. Second, we propose Netlist Babel Fish, a netlist format conversion tool that leverages retrieval-augmented generation (RAG) with a large language model (LLM) to enhance the compatibility of netlist formats. Finally, we build a comprehensive dataset, SpiceNetlist, comprising 775 annotated circuits of 7 different types across 10 component classes. Experiments demonstrate accuracy improvements of 16.08% on SpiceNetlist, 11.38% on Image2Net, and 16.01% on Masala-CHAI compared to the baseline in intra-dataset evaluation, while maintaining accuracy from 92.05% to 99.07% in cross-dataset evaluation, demonstrating robust feature transfer capabilities. However, its linear computational complexity makes processing large-scale netlists challenging and requires future addressing.
-
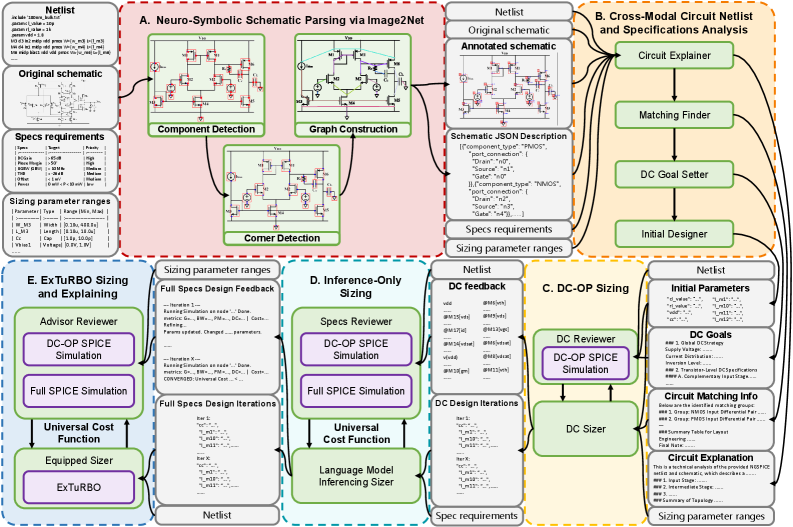 VLM-CAD: VLM-Optimized Collaborative Agent Design Workflow for Analog Circuit SizingGuanyuan Pan, Shuai Wang, Yugui Lin, and 4 more authors2026
VLM-CAD: VLM-Optimized Collaborative Agent Design Workflow for Analog Circuit SizingGuanyuan Pan, Shuai Wang, Yugui Lin, and 4 more authors2026Analog mixed-signal circuit sizing involves complex trade-offs within high-dimensional design spaces. Existing automatic analog circuit sizing approaches rely solely on netlists, ignoring the circuit schematic, which hinders the cognitive link between the schematic and its performance. Furthermore, the black-box nature of machine learning methods and hallucination risks in large language models fail to provide the necessary ground-truth explainability required for industrial sign-off. To address these challenges, we propose a Vision Language Model-optimized collaborative agent design workflow (VLM-CAD), which analyzes circuits, optimizes DC operating points, performs inference-based sizing, and executes external sizing optimization. We integrate Image2Net to annotate circuit schematics and generate a structured JSON description for precise interpretation by Vision Language Models. Furthermore, we propose an Explainable Trust Region Bayesian Optimization method (ExTuRBO) that employs collaborative warm-start from agent-generated seeds and offers dual-granularity sensitivity analysis for external sizing optimization, supporting a comprehensive final design report. Experiment results on amplifier sizing tasks using 180nm, 90nm, and 45nm Predictive Technology Models demonstrate that VLM-CAD effectively balances power and performance while maintaining physics-based explainability. VLM-CAD meets all specification requirements while maintaining low power consumption in optimizing an amplifier with a complementary input and a class-AB output stage, with a total runtime under 66 minutes across all experiments on two amplifiers.
- TSM-Pose: Topology-Aware Learning with Semantic Mamba for Category-Level Object Pose EstimationJinshuo Liu, Bingtao Ma, Junlin Su, and 6 more authorsIn , 2026
Category-level object pose estimation is fundamental for embodied intelligence, yet achieving robust generalization to unseen instances remains challenging. However, existing methods mainly rely on simple feature extraction and aggregation, which struggle to capture category-shared topological structures and conduct semantic keypoint modeling, limiting their generalization. To address these, we propose a Topology-Aware Learning with Semantic Mamba for Category-Level Pose Estimation framework (TSM-Pose). Specifically, we introduce a Topology Extractor to capture the global topological representation of the point cloud, which is integrated into local geometry features and enables robust category-level structural representation. Simultaneously, we propose a Mamba-based Global Semantic Aggregator that injects semantics priors into keypoints to enhance their expressiveness and leverages multiple TwinMamba blocks to model long-range dependencies for more effective global feature aggregation. Extensive experiments on three benchmark datasets (REAL275, CAMERA25, and HouseCat6D) demonstrate that TSM-Pose outperforms existing state-of-the-art methods.
- Uncertainty-Gated Dual-path Probabilistic Depth Fusion for Robot ManipulationTiansheng Zhou, Bingtao Ma, Chalermchon Satirapod, and 5 more authorsIn Proceedings of the 41st Youth Academic Annual Conference of Chinese Association of Automation (YAC), 2026
2025
- Physics-Informed Temporal Generative Adversarial Networks: A Potent Tool for Lithium Battery Data GenerationChenyu Lin, Qiqi Chen, \textbfG. Pan, and 3 more authorsIn 2025 9th International Symposium on Computer Science and Intelligent Control (ISCSIC), 2025
Accurately predicting the aging process of lithium batteries is essential for battery health management and predictive maintenance. However, the scarcity of real aging data limits the reliability of existing models. To address this issue, this paper proposes a Physics-Informed Temporal Generative Adversarial Network (PITGAN)-based framework for generating multi-dimensional time-series battery data to support health assessment. The framework integrates temperature-aware feature embedding to dynamically incorporate thermal environment characteristics and utilizes a hybrid GRU-convolutional architecture to capture long-range temporal dependencies and local electrochemical features. Additionally, an improved GAN method is proposed, combining the conditional control capability of CGAN with the smooth optimization characteristics of WGAN-GP to enhance training stability and improve the authenticity of the generated data. The feature extraction module preserves the physical constraints of voltage-capacity curves, while the generator-discriminator structure enables joint modeling of multi-dimensional data distributions. The analysis of experimental results shows that the generated data closely resembles actual data in terms of distribution, with a voltage-capacity curve error of less than 1.8 %. Furthermore, state-of-charge and state-of-health estimation models trained on the generated data achieve a mean absolute error below 3.2%.
2024
- A Novel Fusion Network for Apple Image Classification and Quantity RecognitionHanyu Jiang, Zhipeng Wang, Jiahan Chen, and 2 more authorsIn Proceedings of the International Conference on Computer Vision and Deep Learning (CVDL ’24), 2024
We focuses on identifying images containing apples from a large number of orchard fruit images and determining the number of apples in each filtered image. We propose a CV5Fnet model that combines traditional OpenCV image processing operations with the Watershed Algorithm and YOLO V5. We first build a high-precision, lightweight fruit classifier to accurately filter apple images from five fruit images in the dataset, and pass apple images to the red apple recognition module and the green apple recognition module based on YOLOV5, which are based on the filters, HSV color space conversion, masking operations, and Watershed Algorithm, respectively. The apple pictures are passed to the red apple recognition module based on filter, HSV color space conversion, mask operation, watershed algorithm and the green apple recognition module based on YOLOV5 to recognize the number of red apples and the number of green apples in the target pictures. and green apples in the target picture respectively, and finally sum up to the number of apples in the picture. In the publicly available dataset 2023APMCM_A_2, the accuracy of our fruit classifier is as high as 99.86%, and the final image processing results show that CV5Fnet has achieved good results in recognizing the number of apples.